
Tanto Java como Elasticsearch son elementos populares dentro de los stacks de tecnología comunes que utilizan las empresas. Java es un lenguaje de programación que se lanzó en 1996. Java es propiedad de Oracle y todavía está en desarrollo activo.
Elasticsearch es una tecnología joven en comparación con Java; solo se lanzó en 2010 (lo que la hace 14 años más joven que Java). Está ganando popularidad rápidamente y ahora se utiliza en muchas empresas como motor de búsqueda.
Al ver lo populares que son ambos, muchas personas y empresas quieren conectar Java con Elasticsearch para desarrollar su propio motor de búsqueda. En este artículo, quiero enseñarle cómo conectar Java Spring Boot 2 con Elasticsearch. Aprenderemos a crear una API que llamará a Elasticsearch para producir resultados.
Conectando Java con Elasticsearch
Lo primero que debemos hacer es conectar nuestro proyecto Spring Boot con Elasticsearch. La forma más fácil de hacer esto es usar la biblioteca cliente proporcionada por Elasticsearch, que podemos agregar a nuestro administrador de paquetes (como Maven o Gradle).
Para este artículo, usaremos una biblioteca spring-data-elasticsearch proporcionada por Spring Data, que también incluye la biblioteca de cliente de alto nivel de Elasticsearch.
Comencemos por crear nuestro proyecto Spring Boot con Spring Initialzr. Configuraré mi proyecto para que sea como la imagen a continuación, ya que vamos a utilizar un cliente de alto nivel. Luego, podemos usar una biblioteca conveniente proporcionada por Spring, Spring Data Elasticsearch:
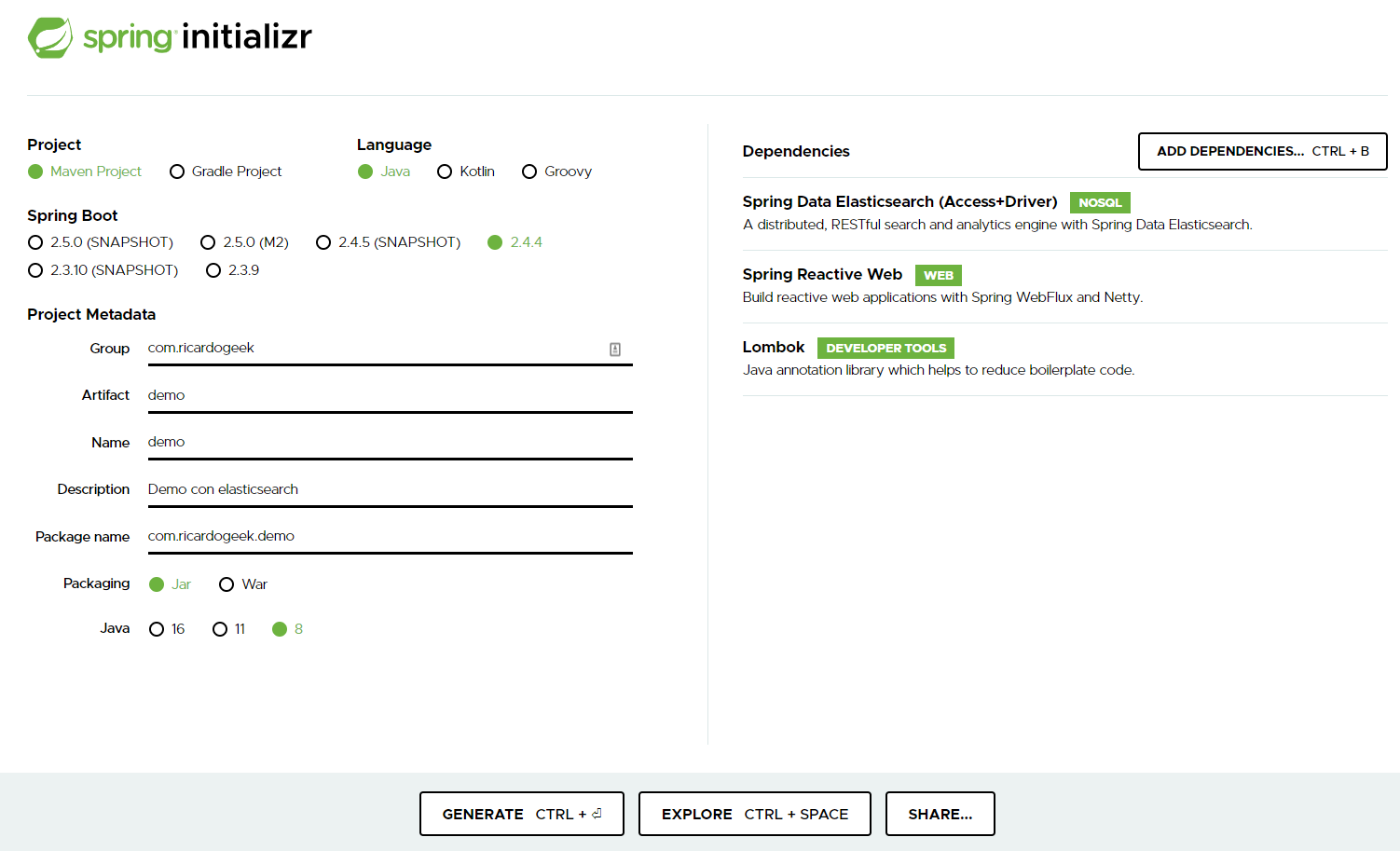
Al generar un proyecto con este conveniente formulario ya tenemos todas las dependencias preconfiguradas en un proyecto de maven y lo único que queda es abrirlo con nuestro IDE favorito (IntelliJ) y ponernos manos a la obra.
Creando el bean del cliente Elasticsearch
Hay dos métodos para inicializar el bean: puede utilizar los beans definidos en la biblioteca Spring Data Elasticsearch o puede crear su propio bean.
La opción más sencilla es utilizar el bean configurado por Spring Data Elasticsearch.
Por ejemplo, puede agregar estas propiedades en su application.properties:
spring.elasticsearch.rest.uris=localhost:9200
spring.elasticsearch.rest.connection-timeout=1s
spring.elasticsearch.rest.read-timeout=1m
spring.elasticsearch.rest.password=
spring.elasticsearch.rest.username=El segundo método consiste en crear su propio bean. Puede configurar los ajustes creando el bean RestHighLevelClient. Si el bean existe, Spring Data lo usará como configuración.
@Configuration
@RequiredArgsConstructor
public class ElasticsearchConfiguration extends AbstractElasticsearchConfiguration {
private final ElasticsearchProperties elasticsearchProperties;
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo(elasticsearchProperties.getHostAndPort())
.withConnectTimeout(elasticsearchProperties.getConnectTimeout())
.withSocketTimeout(elasticsearchProperties.getSocketTimeout())
.build();
return RestClients.create(clientConfiguration).rest();
}
}Debemos respetar los nombres en ingles de esta clase o de lo contrario nuestra configuración no tomará efecto.
Probando la conexión de nuestra aplicación Spring Boot a Elasticsearch
Su aplicación Spring Boot y Elasticsearch deberían estar conectados ahora que ha configurado el bean. Ya que vamos a probar la conexión, asegúrese de que su Elasticsearch esté en funcionamiento.
Para probarlo, podemos crear un bean que creará un índice en Elasticsearch en DemoApplication.java. La clase se vería así:
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Bean
public boolean createTestIndex(RestHighLevelClient restHighLevelClient) throws Exception {
try {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("hello-world");
restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT); // 1
} catch (Exception ignored) { }
CreateIndexRequest createIndexRequest = new CreateIndexRequest("hello-world");
createIndexRequest.settings(
Settings.builder().put("index.number_of_shards", 1)
.put("index.number_of_replicas", 0));
restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT); // 2
return true;
}
}Bien, en ese código llamamos a Elasticsearch dos veces con RestHighLevelClient, que aprenderemos más adelante en este artículo. La primera llamada es eliminar el índice “hello-world” si ya existe. Usamos un try / catch eso, porque si el índice, no existe elasticsearch arrojará un error, fallando el proceso de inicio de nuestra aplicación, por eso simplemente ignoramos el error ya que esta bien que no exista, adicionalmente podriamos agregar algunos logs.
La segunda llamada es crear un índice. Como solo estoy ejecutando un Elasticsearch de un solo nodo, configuré los fragmentos (shards) en 1 y las réplicas en 0.
Si todo salió bien, entonces debería ver los índices cuando revise su Elasticsearch. Para comprobarlo, vaya a http://localhost:9200/_cat/indices?v, y podrá ver la lista de índices en su Elasticsearch.
Otras formas de conectarse
Les recomiendo que use la biblioteca spring-data-elasticsearch si desea conectarse a Elasticsearch con Java. Pero si no puede usar esa biblioteca, existe otra forma de conectar sus aplicaciones a Elasticsearch.
Cliente High Level
Como sabemos por la sección anterior, la biblioteca spring-data-elasticsearch que usamos también incluye el cliente de alto nivel de Elasticsearch. Si ya ha importado spring-data-elasticsearch, entonces ya puede usar el cliente de alto nivel de Elasticsearch.
Si lo desea, también es posible utilizar la biblioteca de High Level Client directamente sin la dependencia de Spring Data. Solo necesita agregar esta dependencia en su administrador de dependencias:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>8.0.0</version>
</dependency>También usaremos este cliente en nuestros ejemplos porque la funcionalidad en el cliente de alto nivel es más completa que la de spring-data-elasticsearch.
Para obtener más información, puede leer la documentación de Elasticsearch.
Cliente Low Level
Te resultará más difícil con esta biblioteca, pero puedes personalizarla más. Para usarlo, puede agregar la siguiente dependencia:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>8.0.0</version>
</dependency>Para obtener más información, puede leer la documentación de Elasticsearch sobre esto.
Conexión REST
La última forma de conectarse a Elasticsearch es mediante una llamada REST. Dado que Elasticsearch usa la API REST para conectarse a su cliente, básicamente puede usar una llamada REST para conectar sus aplicaciones a Elasticsearch. Puede usar OkHttp, Feign o su cliente web para conectar sus aplicaciones con Elasticsearch.
Tampoco recomiendo este método porque es una molestia. Dado que Elasticsearch ya proporciona bibliotecas cliente, es mejor usarlas en su lugar. Utilice este método solo si no tiene otra forma de conectarse.
Usando Spring Data Elasticsearch
Primero, aprendamos a usar spring-data-elasticsearch en nuestro proyecto Spring. spring-data-elasticsearch es muy fácil de usar y una biblioteca de alto nivel que podemos usar para acceder a Elasticsearch.
Creando una entidad y configurando nuestro índice
Una vez que haya terminado de conectar sus aplicaciones con Elasticsearch, es hora de crear una entidad. Con Spring Data, podemos agregar metadatos a nuestra entidad, que serán leídos por el bean de repositorio que creamos. De esta manera, el código será mucho más limpio y más rápido de desarrollar, ya que no necesitaremos crear ninguna lógica de mapeo en nuestro nivel de servicio.
Creemos una entidad llamada Producto:
@Data
@AllArgsConstructor
@NoArgsConstructor
@Builder
@Document(indexName = "product", shards = 1, replicas = 0, refreshInterval = "5s", createIndex = true)
public class Producto {
@Id
private String id;
@Field(type = FieldType.Text)
private String nombre;
@Field(type = FieldType.Keyword)
private Categoria categoria;
@Field(type = FieldType.Long)
private double precio;
public enum Categoria {
ROPA,
ELECTRONICOS,
JUEGOS;
}
}Así que déjame explicarte lo que está sucediendo en el bloque de código anterior. Primero, no explicaré sobre @Data, @AllArgsConstructor, @NoArgsConstructor y @Builder. Son anotaciones de la biblioteca de Lombok para constructor, captador, definidor, constructor y otras cosas.
Ahora, hablemos de la primera anotación de datos de primavera en la entidad, @Document. La anotación @Document muestra que la clase es una entidad que contiene metadatos de la configuración del índice Elasticsearch. Para usar el repositorio de Spring Data, que aprenderemos más adelante, la anotación @Document es obligatoria.
La única anotación obligatoria en @Document es indexName. Debe quedar bastante claro por el nombre, debemos completarlo con el nombre de índice que queremos usar para la entidad. En este artículo, usaremos el mismo nombre que la entidad, producto.
El segundo parámetro de @Document del que hablar es el parámetro createIndex. Si configura el createIndex como verdadero, sus aplicaciones crearán un índice automáticamente cuando inicie las aplicaciones si el índice aún no existe.
Los parámetros shards, replicas y refreshInterval determinan la configuración del índice cuando se crea el índice. Si cambia el valor de esos parámetros después de que el índice ya está creado, la configuración no se aplicará. Por lo tanto, los parámetros solo se utilizarán al crear el índice por primera vez.
Si desea utilizar una ID personalizada en Elasticsearch, puede utilizar las anotaciones @Id. Si usa anotaciones @Id, Spring Data le dirá a Elasticsearch que almacene la ID en el documento y la fuente del documento.
El tipo @Field determinará la asignación de campo del campo. Al igual que los fragmentos, las réplicas y refreshInterval, el tipo @Field solo afectará a Elasticsearch al crear el índice por primera vez. Si agrega un nuevo campo o cambia los tipos cuando el índice ya está creado, no hará nada.
Ahora que configuramos la entidad, ¡probemos la creación automática de índices por parte de Spring Data! Cuando configuramos el createIndex como verdadero, Spring Data verificará si el índice existe en Elasticsearch. Si no existe, Spring Data creará el índice con la configuración que creamos en la entidad.
Comencemos nuestra aplicación. Después de que se esté ejecutando, verifiquemos la configuración y veamos si es correcta:
curl --request GET \
--url http://localhost:9200/producto/_settingsEl resultado es:
{
"producto": {
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"refresh_interval": "5s",
"number_of_shards": "1",
"provided_name": "producto",
"creation_date": "1607959499342",
"store": {
"type": "fs"
},
"number_of_replicas": "0",
"uuid": "iuoO8lE6QyWVSoECxa0I8w",
"version": {
"created": "7100099"
}
}
}
}
}¡Todo es como lo configuramos! El intervalo de actualización se establece en 5 s, el numero de shards es 1 y el numero de replicas es 0.
Ahora, revisemos las asignaciones:
curl --request GET \
--url http://localhost:9200/producto/_mappingsResulta en:
{
"producto": {
"mappings": {
"properties": {
"categoria": {
"type": "keyword"
},
"nombre": {
"type": "text"
},
"precio": {
"type": "long"
}
}
}
}
}Las asignaciones también son las que esperábamos. Es lo mismo que configuramos en la clase de entidad.
CRUD básico con la interfaz de repositorio de Spring Data
Una vez que hemos creado la entidad, tenemos todo lo que necesitamos para crear una interfaz de repositorio en Spring Boot. Creemos un repositorio llamado ProductoRepository.
Cuando esté creando una interfaz, asegúrese de extender ElasticsearchRepository . En este caso, el objeto T es su entidad y el tipo de objeto U que desea usar para el ID de datos. En nuestro caso, usaremos la entidad Producto que creamos anteriormente como T y String como U.
public interface ProductRepository extends ElasticsearchRepository<Product, String> {
}Ahora que la interfaz de su repositorio está lista, no es necesario que se ocupe de la implementación porque Spring se encarga de ella. Ahora, puede llamar a todas las funciones de las clases a las que se extiende su repositorio.
Para ver ejemplos de CRUD, puede consultar el siguiente código:
@Service
@RequiredArgsConstructor
public class SpringDataProductServiceImpl implements SpringDataProductService {
private final ProductoRepository productoRepository;
public Product createProducto(Producto producto) {
return productoRepository.save(producto);
}
public Optional<Producto> getProducto(String id) {
return productoRepository.findById(id);
}
public void deleteProducto(String id) {
productoRepository.deleteById(id);
}
public Iterable<Producto> insertBulk(List<Producto> productos) {
return productoRepository.saveAll(productos);
}
}En los bloques de código anteriores, creamos una clase de servicio llamada SpringDataProductServiceImpl, que está conectada automáticamente al ProductRepository que creamos antes.
Hay cuatro funciones CRUD básicas en él. El primero es createProduct, que, como su nombre lo indica, creará un nuevo producto en el índice de productos. El segundo, getProduct, obtiene el producto que indexamos por su ID. La función deleteProduct se puede utilizar para eliminar el producto en el índice por ID. La función insertBulk le permitirá insertar varios productos en Elasticsearch.
¡Todo está hecho! No escribiré sobre las pruebas de API en este artículo porque quiero centrarme en cómo nuestras aplicaciones pueden interactuar con Elasticsearch. Pero si quieres probar la API, dejé un enlace de GitHub al final del artículo para que puedas clonar y probar este proyecto.
Métodos de consulta personalizados en Spring Data
En la sección anterior, solo aprovechamos el uso de los métodos básicos que ya están definidos en las otras clases. Pero también podemos crear métodos de consulta personalizados para usar.
Lo que es muy conveniente sobre Spring Data es que puede crear un método en la interfaz del repositorio y no necesita codificar ninguna implementación. La biblioteca Spring Data leerá el repositorio y creará automáticamente las implementaciones para él.
Intentemos buscar productos por el campo de nombre:
Sí, eso es todo lo que necesita hacer para crear una función en la interfaz del repositorio de Spring Data.
También puede definir una consulta personalizada con la anotación @Query e insertar una consulta JSON en los parámetros.
public interface ProductRepository extends ElasticsearchRepository<Producto, String> {
List<Producto> findAllByNombre(String nombre);
@Query("{\"match\":{\"nombre\":\"?0\"}}")
List<Producto> findAllByNombreUsingAnnotations(String nombre);
}Ambos métodos que hemos creado hacen lo mismo: use la consulta de coincidencia con el nombre como parámetro. Si lo prueba, obtendrá los mismos resultados.
Es importante respetar el nombre de los atributos en la firma de los métodos, funciona un poco como magia semántica. Si quisiéramos obtener por precio los métodos deberían llamarse findAllByPrecio y findAllByPrecioUsingAnnotations respectivamente.
Usando ElasticsearchRestTemplate
Si desea realizar una consulta más avanzada, como agregaciones, resaltados o sugerencias, puede usar ElasticsearchsearchRestTemplate proporcionada por la biblioteca Spring Data. Al usarlo, puede crear su propia consulta, haciéndola tan compleja como desee.
Por ejemplo, creemos una función para hacer una consulta de coincidencia con el campo de nombre como antes:
public List<Producto> getProductosByName(String nombre) {
Query query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("nombre", nombre))
.build();
SearchHits<Producto> searchHits = elasticsearchRestTemplate.search(query, Producto.class);
return searchHits.get().map(SearchHit::getContent).collect(Collectors.toList());
}Debería notar que el código anterior es más complejo que el que definimos en ElasticserchRepository. Se recomienda utilizar el repositorio de Spring Data si puede. Pero para una consulta más avanzada como agregación, resaltado o sugerencias, debe usar ElasticsearchRestTemplate.
Por ejemplo, escriba un fragmento de código que agregue un término:
public Map<String, Long> aggregateTerm(String term) {
Query query = new NativeSearchQueryBuilder()
.addAggregation(new TermsAggregationBuilder(term).field(term).size(10))
.build();
SearchHits<Producto> searchHits = elasticsearchRestTemplate.search(query, Producto.class);
Map<String, Long> result = new HashMap<>();
searchHits.getAggregations().asList().forEach(aggregation -> {
((Terms) aggregation).getBuckets()
.forEach(bucket -> result.put(bucket.getKeyAsString(), bucket.getDocCount()));
});
return result;
}Elasticsearch RestHighLevelClient
Si no está usando Spring o su versión de Spring no es compatible con spring-data-elasticsearch, puede usar una biblioteca Java desarrollada por Elasticsearch, RestHighLevelClient.
RestHighLevelClient es una biblioteca que puede usar para hacer cosas básicas como CRUD o administrar su Elasticsearch. Aunque el nombre implica que es un nivel alto, en realidad es un nivel más bajo en comparación con spring-data-elasticsearch.
La ventaja de esta biblioteca sobre Spring Data es que también puede administrar su Elasticsearch con ella. Proporciona una configuración de índice y Elasticsearch, que puede usar con más flexibilidad en comparación con Spring Data. También tiene una funcionalidad más completa para interactuar con Elasticsearch.
La desventaja de esta biblioteca sobre Spring Data es que esta biblioteca es de un nivel más bajo, lo que significa que debe codificar más.
CRUD con RestHighLevelClient
Veamos cómo podemos crear una función simple con la biblioteca para poder compararla con los métodos anteriores que hemos usado:
@Service
@RequiredArgsConstructor
@Slf4j
public class HighLevelClientProductServiceImpl implements HighLevelClientProductService {
private final RestHighLevelClient restHighLevelClient;
private final ObjectMapper objectMapper;
public Product createProducto(Producto producto) {
IndexRequest indexRequest = new IndexRequest("producto");
indexRequest.id(producto.getId());
indexRequest.source(producto);
try {
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
if (indexResponse.status() == RestStatus.ACCEPTED) {
return product;
}
throw new RuntimeException("Wrong status: " + indexResponse.status());
} catch (Exception e) {
log.error("Error indexando, producto: {}", producto, e);
return null;
}
}
}Como puede ver, ahora es más complicado y más difícil de implementar. Ahora, debe manejar la excepción y también convertir el resultado JSON a su entidad. Se recomienda usar Spring Data en su lugar para operaciones CRUD básicas porque RestHighLevelClient es más complicado.
