
El internet hoy en día nos sirve para solucionar una gran cantidad de problemas, gestionar nuestras tareas con mayor facilidad y eficiencia y en general a hacer mejores nuestras vidas. La información esta al alcance de nuestros dedos, prácticamente llevamos la biblioteca de Alejandría todo el tiempo en nuestros bolsillos todo el tiempo.
Pero que pasa cuando queremos ser aun mas eficientes y eficaces en lo que hacemos? que pasa cuando el internet nos ayuda pero hay tareas que son simplemente largas, aburridas y repetitivas y sentimos que podríamos aprovechar mejor el tiempo que nos toma hacerlas enfocándonos en cosas mas importantes?
Aquí es donde entra en juego la automatización de tareas y afortunadamente para nosotros python tiene una amplia colección de herramientas que nos ayudan a efectuar tareas de forma automatizada.
A lo largo de este post estudiaremos las siguientes herramientas:
- requests (http://docs.python-requests.org/en/master/)
- urllib2 (https://docs.python.org/2/library/urllib2.html)
- lxml (https://pypi.org/project/lxml/)
- BeautifulSoup4 (https://pypi.org/project/beautifulsoup4/)
Como caso de uso supongamos que necesitamos monitorear constantemente el tipo de cambio entre el dolar americano (USD) y el peso Mexicano (MXN) para saber el momento en el tiempo en el que me conviene mas cambiar mi dinero y quizás tener alguna estadística de como se comporta.
El primer paso es encontrar una web que provea esta información, yo encontré esta:
https://www.xe.com/es/currencyconverter/convert/?Amount=1&From=USD&To=MXN
Ahora el siguiente paso es encontrar dentro del DOM de la pagina el elemento que contiene el valor que queremos obtener, para eso nos vamos a inspeccionar el elemento. Hacemos clic derecho y seleccionamos “Inspect Element” (en chrome o en firefox)
Cuando seleccionamos esa opción vemos que se abre un apartado en la ventana que nos muestra el código que pinta ese valor:
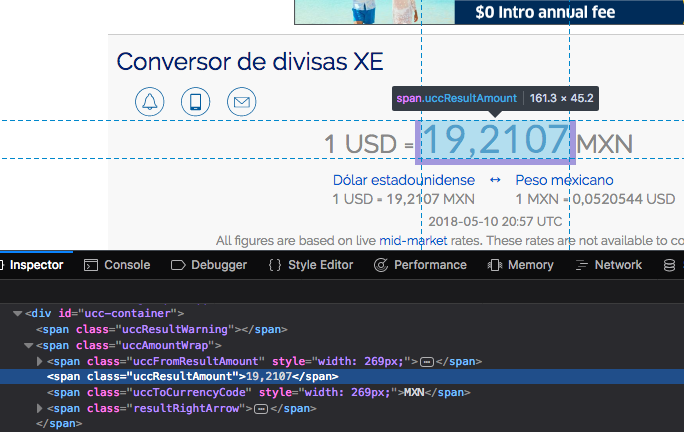
Bingo! notamos el elemento del DOM que tenemos que observar:
<span class="uccResultAmount">19,2107</span>
Ahora bien, antes de continuar vamos a instalar algunas dependencias (requests y lxml), usando pip:
pip install lxml pip install requests
Cuando ya tenemos instaladas estas dependencias, es momento de ponernos manos al código. Bastan 3 lineas para obtener el valor del tipo de cambio:
from lxml import html
import requests
pagina = requests.get('https://www.xe.com/es/currencyconverter/convert/?Amount=1&From=USD&To=MXN')
arbol = html.fromstring(pagina.content)
cambio = arbol.xpath('//span[@class="uccResultAmount"]/text()')
print(cambio)
Esto imprime:
['19,2107']
En este ejemplo nos hemos valido de la dirección xPath para localizar y seleccionar el nodo que contiene el tipo de cambio. Esto no es lo mas cómodo que existe ya que los xpaths pueden ponerse complicados a veces. Así que un grupo de personas decidieron hacerlo mas fácil aun para nosotros y fue así como nació Beautiful Soup, que es una librería que cumple el mismo objetivo que lxml pero mas al estilo de jQuery u otros frameworks de frontend.
Para instalar Beautiful Soup… lo han adivinado, usamos pip:
pip install beautifulsoup4
Veamos ahora unos ejemplos de como usar beautiful soup siempre con la misa pagina del ejemplo anterior:
import bs4
import requests
import lxml
pagina = requests.get('https://www.xe.com/es/currencyconverter/convert/?Amount=1&From=USD&To=MXN')
sopa = bs4.BeautifulSoup(pagina.content, "lxml")
#Enconrando todos los elementos por nombre de tag
print sopa.find_all('a')
print sopa.find_all('span')
#Encontrar un elemento con un id especifico
print sopa.find('span', { "class": "uccResultAmount" })
Si combinamos los poderes de Beautiful Soup con un poco de urlib2 para manipular archivos remotos, podemos hacer un pequeño script que descarga todas las imágenes de una página
from bs4 import BeautifulSoup
import re
import urllib2
import os
## Parametros de descarga
image_type = "Project"
movie = "Avatar"
url = "https://www.google.com/search?q="+movie+"&source=lnms&tbm=isch"
#Obtenemos el resultado de la busqueda con urlib2 y hacemos una sopa con eso
header = {'User-Agent': 'Mozilla/5.0'}
soup = BeautifulSoup(urllib2.urlopen(urllib2.Request(url,headers=header)))
#Obtenemos los elementos de imagen que en el atributo src tengan gstatic.com (que es donde google almacena sus imagenes)
images = [a['src'] for a in soup.find_all("img", {"src": re.compile("gstatic.com")})][:5]
#Descargamos las imagenes y las escribimos
for img in images:
raw_img = urllib2.urlopen(img).read()
cntr = len([i for i in os.listdir(".") if image_type in i]) + 1
#escribimos el archivo
f = open(image_type + "_"+ str(cntr)+".jpg", 'wb')
f.write(raw_img)
f.close()
Conclusión
Entonces así cubrimos las bases del web scraping con python, como podrán darse cuenta bastan unas cuantas lineas de código para comenzar a minar datos de internet, o bien, descargar coleccione de archivos para su posterior uso.
El uso que se le de a este conocimiento debe ser usado con la responsabilidad del caso ya que podría, en algunas ocasiones, tener implicaciones legales, siempre revisen los términos de uso de los datos que estén recopilando.
[…] Lo siguiente seria localizar los campos de usuario y contraseña por medio de sus nombres (parecido a como lo hicimos en el post anterior) […]
[…] utilizar es el Scraping. Hay en Python dos módulos preparados para eso. Request y Lxml y del buen sitio que lo aprendí (gracias ? ). También con la herramienta Pip de python los instalas en un […]