
En este artículo, me gustaría compartir un enfoque diferente sobre este tema, y también hablar sobre algunas particularidades y conceptos erróneos sobre volátiles. Hay muy buen material sobre este tema (como “Java Concurrency In Practice“).
Los animo a leerlo 😉
Hablaremos de la semántica de volátil como se define a partir de Java 5 en adelante (en versiones anteriores de Java, volátil no tiene semántica de consistencia de memoria/visibilidad de estado).
Concurrencia de Java: ¿Qué es volatile?
Respuesta corta: volatile es una palabra clave que podemos aplicar a un campo para garantizar que cuando un subproceso escribe un valor en ese campo, el valor escrito está “inmediatamente disponible” para cualquier subproceso que lo lea posteriormente (característica de visibilidad).
Contexto
Cuando varios hilos necesitan interactuar con algunos datos compartidos, hay tres aspectos a considerar:
- Visibilidad: los efectos de una acción en los datos compartidos por un subproceso deben ser observables por otros subprocesos (vistas coherentes);
- Ordenación: el orden de ejecución debe ser el mismo que el de las declaraciones que aparecen en el código fuente (coherencia secuencial);
- Atomicidad: ningún subproceso debe interferir mientras otro subproceso ejecuta algunas acciones en los datos compartidos.
En ausencia de las sincronizaciones necesarias, el compilador, el tiempo de ejecución o los procesadores pueden aplicar todo tipo de optimizaciones, como el reordenamiento del código y el almacenamiento en caché. Esas optimizaciones pueden interactuar con el código sincronizado incorrectamente de maneras que no son inmediatamente obvias cuando se examina el código fuente. Incluso si las declaraciones se ejecutan en el orden en que aparecen en un subproceso, el almacenamiento en caché puede evitar que los valores más recientes se reflejen en la memoria principal.
Para evitar resultados incorrectos o impredecibles, podemos usar (alguna forma de) sincronización.
Vale la pena mencionar que la sincronización no implica el uso de la palabra clave synchronized (que se basa internamente en bloqueos implícitos/supervisados/intrínsecos); por ejemplo, los objetos de bloqueo y la palabra clave volatile también son mecanismos de sincronización.
En un contexto de subprocesos múltiples, generalmente debemos recurrir a la sincronización explícita. Pero, en escenarios particulares, existen algunas alternativas que podríamos usar que no dependen de la sincronización, como métodos atómicos y objetos inmutables.
Para ilustrar los riesgos de un programa no sincronizado correctamente, consideremos el siguiente ejemplo. ¡Este programa podría simplemente imprimir 42, o incluso imprimir 0, o incluso colgarse para siempre!
@NotThreadSafe
public class NoVisibility {
private static boolean ready;
private static int number;
private static class ReaderThread extends Thread {
public void run() {
while (!ready)
Thread.yield();
System.out.println(number);
}
}
public static void main(String[] args) {
new ReaderThread().start();
number = 42;
ready = true;
}
}
// (extracto del libro Java concurrency in practice)¿Por qué podría pasar esto? En Java, por defecto, se supone que una pieza de código es ejecutada por un solo hilo. Como vimos, el compilador, el tiempo de ejecución o el procesador podrían optimizar las cosas, siempre que obtengamos el mismo resultado que con el código original. En un contexto de subprocesos múltiples, es responsabilidad del desarrollador usar los mecanismos apropiados para sincronizar correctamente los accesos a un estado compartido.
En este ejemplo en particular, el compilador pudo ver que ‘ready’ es falso (valor predeterminado) y nunca cambia, por lo que terminaríamos con un bucle infinito. Por otro lado, si el valor actualizado para “listo” es visible para ReaderThread antes de que “número” sea (reordenación de código/almacenamiento en caché), ReaderThread verá que “número” es 0 (valor predeterminado).
La relación happens-before
“Dos acciones pueden ser ordenadas por una relación que sucede antes. Si ocurre una acción antes que otra, entonces la primera es visible y se ordena antes que la segunda (por ejemplo, la escritura de un valor predeterminado en cada campo de un objeto construido por un subproceso no necesita ocurrir antes del comienzo de ese subproceso, siempre y cuando ninguna lectura observe ese hecho).
sección 17.4.5
Más específicamente, si dos acciones comparten una relación de suceso anterior, no necesariamente tienen que parecer que han ocurrido en ese orden para ningún código con el que no compartan una relación de happens-before“.
Esta relación se establece por:
- La construcción synchronized (esto también proporciona atomicidad);
- La construcción volatile;
- Métodos Thread.start() y Thread.join();
- Los métodos de todas las clases en java.util.concurrent y sus subpaquetes;
Para entender la importancia de esta relación, repasemos el concepto de carrera de datos. “Una carrera de datos ocurre cuando al menos un subproceso escribe en una variable y al menos otro subproceso lee, y las lecturas y escrituras no están ordenadas por una relación que sucede antes. Un programa correctamente sincronizado es uno sin carreras de datos”.
Más específicamente: un programa correctamente sincronizado es aquel cuyas ejecuciones secuencialmente consistentes no tienen carreras de datos.
Volatile
volatile es una forma ligera de sincronización que aborda los aspectos de visibilidad y orden. volatile se utiliza como modificador de campo. El propósito de volatile es garantizar que cuando un subproceso escribe un valor en un campo, el valor escrito está “inmediatamente disponible” para cualquier subproceso que lo lea posteriormente.
Hay un concepto erróneo común sobre la relación entre volátiles, por un lado, y referencias y objetos, por el otro. En Java, hay objetos y referencias a esos objetos. Podemos pensar en las referencias como “punteros” a objetos. Todas las variables (excepto las primitivas como booleanas o longs) contienen referencias (referencias a objetos). volatile actúa sobre una variable primitiva o sobre una variable de referencia. No hay relación entre volátil y el objeto al que se refiere la variable (referencia).
Declarar una variable compartida como volátil garantiza la visibilidad.
Las variables volátiles no se almacenan en caché en registros o cachés donde se ocultan de otros procesadores, por lo que una lectura de una variable volátil siempre devuelve la escritura más reciente de cualquier subproceso.
“Los efectos de visibilidad de las variables volátiles se extienden más allá del valor de la propia variable volátil. Cuando el subproceso A escribe en una variable volátil y, posteriormente, el subproceso B lee esa misma variable, los valores de todas las variables que eran visibles para A antes de escribir en la variable volátil se vuelven visibles para B después de leer la variable volátil”.
del libro JCIP
Para garantizar que los resultados de una acción sean observables para una segunda acción, entonces la primera debe ocurrir antes que la segunda.
volatile también limita el reordenamiento de los accesos (accesos a la referencia) al evitar que el compilador y Runtime reordenen el código. La capacidad de percibir restricciones de orden entre acciones solo está garantizada para acciones que comparten una relación de “sucede antes” con ellas.
Bajo el capó, la volatilidad hace que las lecturas y escrituras vayan acompañadas de una instrucción especial de la CPU conocida como barrera de memoria. Para obtener más detalles de bajo nivel, puede consultar aquí y aquí.
Desde la perspectiva de la visibilidad de la memoria, escribir una variable volatile es como salir de un bloque synchronized y leer una variable volatile es como entrar en un bloque synchronized. Pero tenga en cuenta que volátil no bloquea como lo hace synchronized.
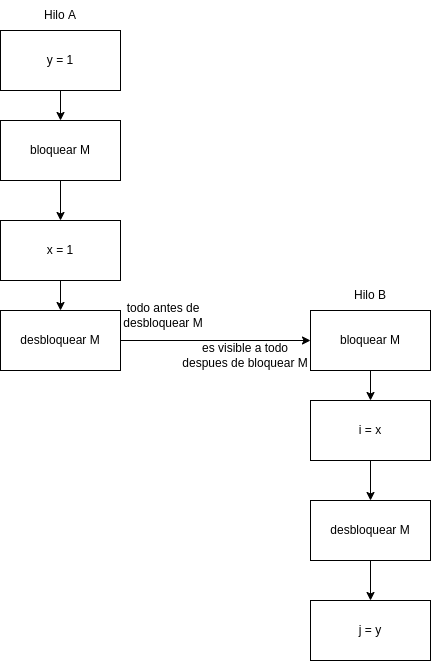
Una acción atómica en la programación concurrente es aquella que ocurre completamente o no ocurre en absoluto. Ningún efecto secundario de una acción atómica es visible hasta que se completa la acción.
Existe una correlación entre las acciones volátiles y atómicas: para las variables primitivas numéricas (largas y dobles) de 64 bits no volátiles, la JVM es libre de tratar una lectura o escritura de 64 bits como dos operaciones separadas de 32 bits. El uso de volatile en esos tipos garantiza que las operaciones de lectura y escritura sean atómicas (el acceso al resto de las variables primitivas y las variables de referencia es atómico por defecto). los accesos volátiles no garantizan la atomicidad de las operaciones compuestas, como incrementar un contador. Las operaciones compuestas en variables compartidas deben realizarse atómicamente para evitar carreras de datos y condiciones de carrera.
Cuándo usar volatile
Podemos usar variables volatile solo cuando se cumplen todos los siguientes criterios:
- Las escrituras en la variable no dependen de su valor actual, o puede asegurarse de que solo un subproceso actualice el valor;
- La variable no participa en invariantes con otras variables de estado
- El bloqueo no es necesario por ningún otro motivo mientras se accede a la variable.\
Algunos escenarios adecuados son:
- Cuando tenemos un indicador simple (como un indicador de finalización, interrupción o estado) u otro elemento primitivo de datos al que acceden (leen) varios subprocesos;
- Cuando tenemos un objeto inmutable más complejo que es inicializado por un subproceso y luego acceden otros: aquí queremos actualizar la referencia a la estructura de datos inmutable y permitir que otros subprocesos hagan referencia a ella.
Consideraciones antes de usar volatile
- El código que se basa en variables volatile para la visibilidad del estado arbitrario es más frágil y más difícil de entender que el código que usa bloqueo;
- La semántica de volatile no es lo suficientemente sólida como para garantizar la atomicidad (las variables atómicas brindan soporte atómico de lectura, modificación y escritura y, a menudo, se pueden usar como “mejores variables volatile“).
- La sincronización puede introducir contención de subprocesos, lo que ocurre cuando dos o más subprocesos intentan acceder al mismo recurso simultáneamente.
Ejemplos
Incrementando un contador
@NotThreadSafe
public class UnsafeCounter {
private volatile Integer counter;
public void increment() {
counter++;
}
}Aunque aparece como una sola operación, la declaracion “counter++;” no es atómica. En realidad, es una combinación de tres operaciones diferentes: leer, actualizar, escribir. Por lo tanto, incluso hacer que el contador sea volátil no es suficiente para evitar carreras de datos en un contexto de subprocesos múltiples: podemos terminar con actualizaciones perdidas.
Algunas alternativas seguras para subprocesos: synchronized, AtomicInteger.
Patrón Singleton con inicialización diferida
@ThreadSafe
public class Singleton {
private static volatile Singleton INSTANCE;
private Singleton() {
}
public static Singleton getInstance() {
if (INSTANCE != null)
return singleton;
synchronized (Singleton.class) {
if (INSTANCE == null)
INSTANCE = new Singleton();
return INSTANCE;
}
}
}En este caso, no hacer que INSTANCE sea volátil podría hacer que getInstance() devuelva un objeto no inicializado por completo, rompiendo el patrón Singleton. ¿Por qué? La asignación de la variable de referencia INSTANCE podría ocurrir mientras se inicializa el objeto, exponiendo a otros subprocesos un estado (incorrecto) que terminará cambiando, ¡incluso si el objeto es inmutable! Usando volatile, podemos garantizar una publicación segura única del objeto.
Colaborador inmutable
// Immutable Helper
public final class Helper {
private final int n;
public Helper(int n) {
this.n = n;
}
// ...
}
// Mutable Foo
@NotThreadSafe
final class Foo {
private Helper helper;
public Helper getHelper() {
return helper;
}
public void setHelper(int num) {
helper = new Helper(num);
}
}Aunque Foo (mutable) contiene campos que se refieren solo a objetos inmutables (Helper), Foo no es seguro para subprocesos. Es posible que los objetos mutables no se construyan por completo cuando sus referencias se hacen visibles. La razón es que, mientras que el objeto compartido (Helper) es inmutable, la referencia utilizada para acceder a él es compartida y mutable. En el ejemplo, eso significa que un subproceso separado podría observar una referencia obsoleta en el campo auxiliar del objeto Foo. Una solución a ese problema podría ser hacer que el campo auxiliar de Foo sea volátil; volatile garantiza que un objeto se construye correctamente antes de que su referencia se haga visible.
Operación compuesta
@NotThreadSafe
final class Flag {
private volatile boolean flag = true;
public void toggle() { // Unsafe
flag ^= true;
}
public boolean getFlag() { // Safe
return flag;
}
}Como en el primer ejemplo que vimos, aquí tenemos una operación compuesta.
volátil no es suficiente en este caso.
En fin…
las variables volatile son una forma de sincronización más débil que el bloqueo, que en algunos casos son una buena alternativa al bloqueo. Si seguimos las condiciones para usar volatile que discutimos, tal vez podamos lograr la seguridad de subprocesos y un mejor rendimiento que con el bloqueo. Sin embargo, el código que usa volatile suele ser más frágil que el código que usa bloqueo.
volatile no es solo una alternativa al bloqueo (en algunos casos); tiene sus propios usos, también. volatile se puede combinar con otros mecanismos de sincronización, pero generalmente es mejor usar solo un mecanismo en un estado compartido particular.
Como volatile no bloquea (a diferencia de synchronized), no hay posibilidad de que se produzcan interbloqueos. Pero, al igual que otros mecanismos de sincronización, el uso de volátiles implica algunas penalizaciones de rendimiento.
En contextos muy disputados, el uso de volatile podría ser perjudicial para el rendimiento.
Tenga en cuenta que volatile solo se aplica a los campos. No tendría sentido aplicarlo a parámetros de método o variables locales dado que todos son locales/privados para el subproceso en ejecución.
volatile está relacionado con referencias a objetos y no con operaciones en los objetos en sí.
Usar el acceso a variables atómicas simples es más eficiente que acceder a estas variables a través de código sincronizado, pero requiere más cuidado por parte del programador para evitar errores de coherencia de memoria. Si el esfuerzo adicional vale la pena depende del tamaño y la complejidad de la aplicación.
