
Como en el post anterior hemos aprendido como instalar jenkins continuamos con los primeros pasos de configuración que tenemos que hacer para lograr usarlo en nuestro proceso de integración continua. Y ademas crearemos nuestro primer job básico que solo imprime hola mundo
Bien, lo primero es acceder a nuestra instancia de jenkins a través del puerto 8080, y lo primero que veremos es el asistente de configuración que nos pide la contraseña auto generada para “desbloquear” nuestra instancia.
Para obtener dicha contraseña hay que revisar el archivo que indica, asi:
cat /var/lib/jenkins/secrets/initialAdminPassword
Y copiamos y pegamos la contraseña en el cuadro de texto que lo indica. Y a continuación hacemos click en “continue”
A continuación el asistente nos pregunta si quisiéramos instalar algunos aditamentos en especial o si nos gustaría continuar con la versión dogmática. Para este tutorial vamos a elegir usar la versión por defecto, por lo que unicamente hacemos clic en esa opción.

Después se nos presenta esta pantalla en donde podemos llevar un seguimiento visual de todo lo que el asistente esta haciendo.
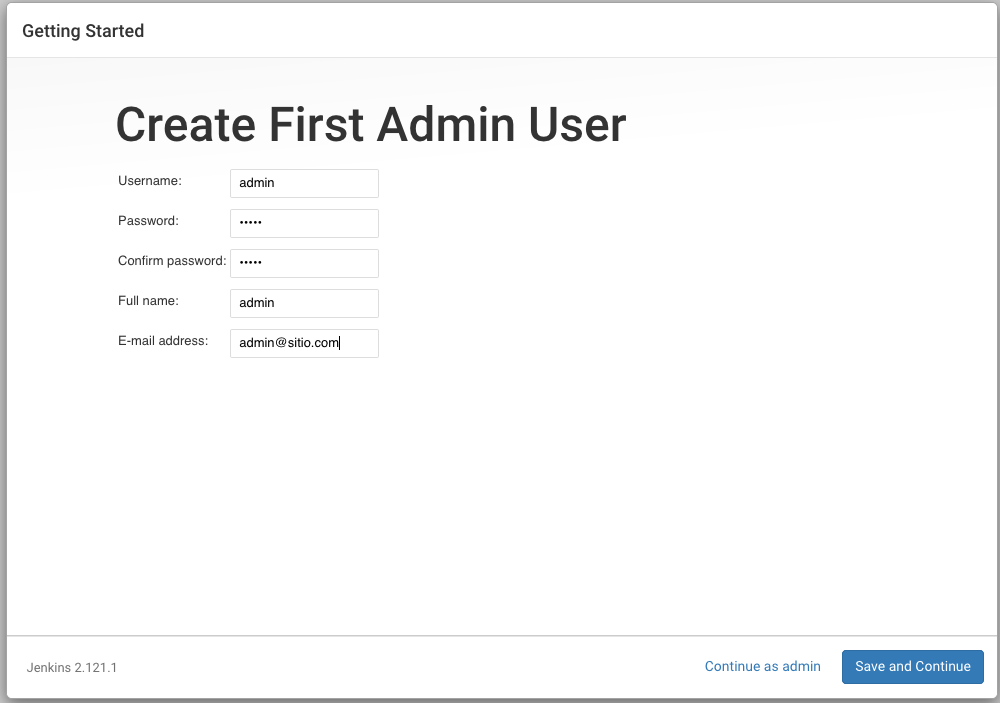
Cuando el asistente termina de instalar todos los plugins necesarios nos pide que creemos un usuario administrador que gestionara esta instancia para lo cual llenamos el formulario:
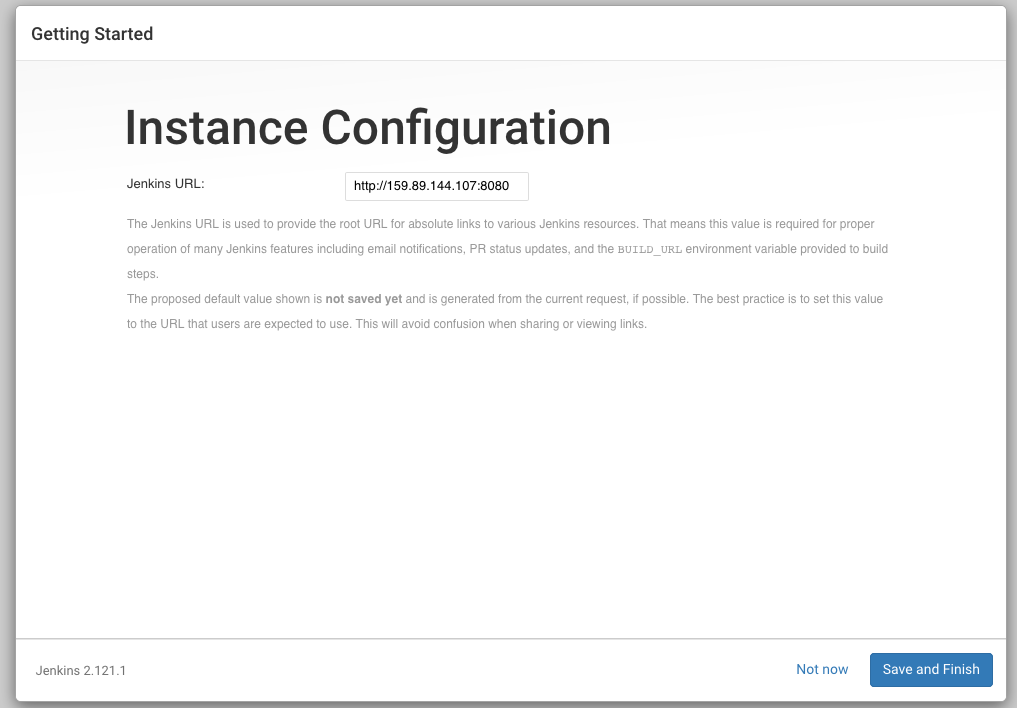
Finalmente tenemos que configurar la instancia, dándole la URL final que ocupara esta instalación como en este caso no tenemos un dominio especifico lo dejamos con la dirección IP del servidor que estamos configurando.
Y finalmente estamos listos para comenzar a usar Jenkins. Al hacer click en el botón “Start using Jenkins” nos llevara a la pagina principal.
En la página principal podemos ver varias opciones para comenzar a configurar nuestros jobs.
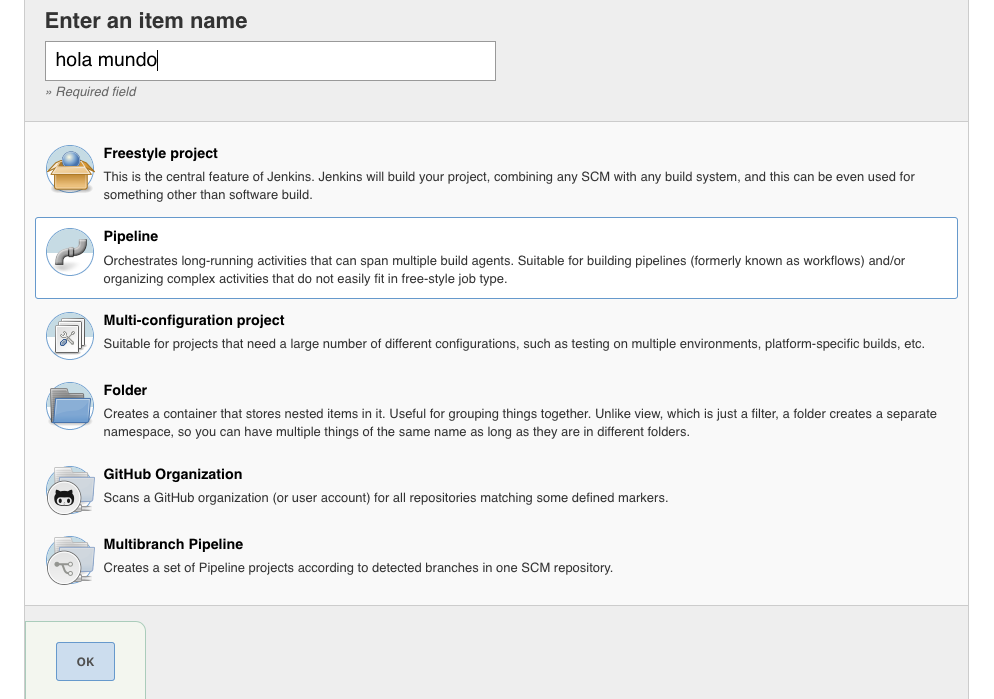
Para crear nuestro primer job hacemos click en “New Item” y seleccionamos “pipeline” y de nombre le ponemos “hola mundo”
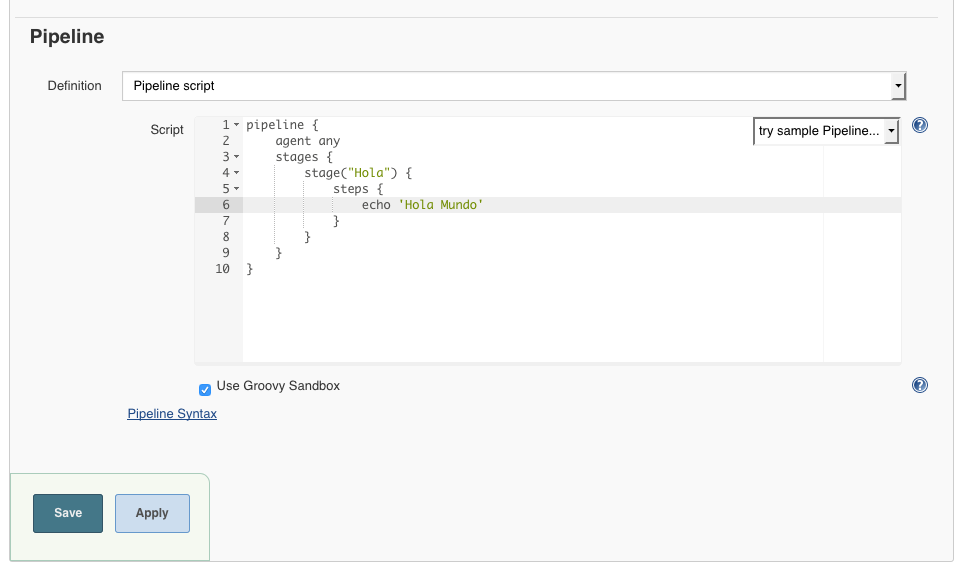
Luego hacemos click en “OK” y se nos presenta la pagina de configuración del pipeline que acabamos de crear. En este punto hay muchas opciones que se pueden configurar, pero para efectos de este tutorial vamos a ir directo a la sección que pone “Pipeline” y vemos que hay un área de texto con la etiqueta “Script”
Aquí es donde configuramos las etapas de nuestro pipeline. Lo que ponemos en esta área es un script en lenguaje groovy para configurar los pasos que debe tomar el proceso de integración.
Aquí hay un script de ejemplo que podes copiar y pegar:
pipeline {
agent any
stages {
stage("Hola") {
steps {
echo 'Hola Mundo'
}
}
}
}
Se ve asi:
Cuando hacemos clic en “Save” el pipline se guarda y nos lleva automáticamente a la pagina donde están los jobs:
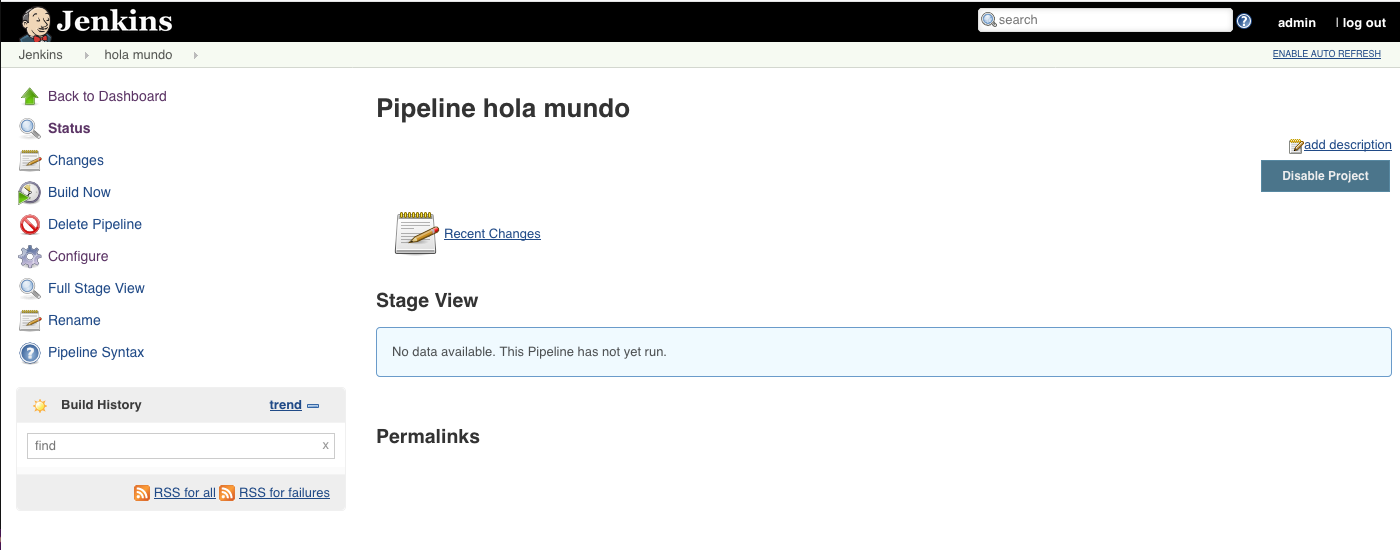
Cuando en esta página hacemos clic en “Build Now” aparece un mensaje de que la compilación ha sido agendada (build scheduled) y podemos ver el progreso en la sección de la izquierda que pone “Build History”
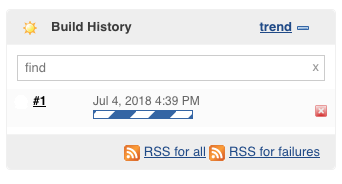
Cuando termina en la sección principal podemos ver el resultado de cada uno de las etapas (stages) del build
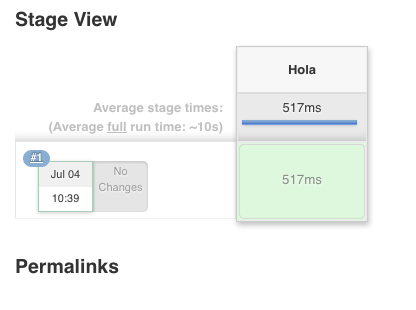
Y cuando hacemos clic en la sección verde y luego en “logs” una ventana aparece con los resultados de consola que dio la etapa en cuestión. Para nuestro caso particular, “Hola Mundo”.
Este ejemplo se ejecuto en 10 segundos, lo cual es un tiempo bastante bueno. De cualquier manera un pipeline de la vida real es mucho mas complejo y toma mucho mas tiempo en tareas como descargar los repositorios, compilar código fuente, ejecutar pruebas. Entonces un solo build puede tomar desde algunos minutos a horas de trabajo.
En escenarios comunes, también hay varios pipelines concurrentes y usualmente, todo un equipo, o incluso toda una organización usa la misma instancia de jenkins. Cuando muchos usuarios utilizan la misma instancia de jenkins resulta muy fácil que esta se ahogue en el camino y no sea capaz de atender a todos, por lo que en ocasiones es recomendable configurar varias instancias de jenkins en una arquitectura “master-slave” que estudiaremos en posts subsecuentes a este.
[…] el jenkins job inicia, el master corre un nuevo contenedor desde la imagen jenkins-slave en el host […]