
Muchas personas tienden a agregar mucho misticismo al algoritmo de búsqueda de Google (también conocido como Page Rank) porque de alguna manera siempre se las arregla para mostrarnos el resultado que estamos buscando en las primeras páginas (incluso en los casos en que hay cientos de páginas de resultados).
¿Como funciona? ¿Por qué es tan preciso? No hay una respuesta real a esas preguntas a menos que, por supuesto, seas parte del equipo dentro de Google trabajando para mantenerla.
Sin tener que entrar en los servidores de Google y robar su algoritmo, podemos resolver algo que nos dará una función de búsqueda muy poderosa que puede integrar fácilmente en su sitio / aplicación web con muy poco esfuerzo y al mismo tiempo lograr una gran experiencia de usuario.
Básicamente me refiero a lo que normalmente se conoce como “búsqueda de texto completo” o en ingles “full text search”. Si tienes alguna experiencia en desarrollo web tradicional, probablemente estés acostumbrado a tener una base de datos SQL, como MySQL o PostgreSQL, que por defecto le permite realizar búsquedas basadas en comodines en sus campos de cadena, como:
SELECT * FROM Ciudades WHERE nombre like 'Nueva%';Usando la consulta anterior, generalmente obtendría resultados coincidentes como:
- Nueva York
- Nueva Delhi
- Nueva Orleans
El motor de la base de datos obtiene el patrón, y si tuviera datos más complejos dentro de su base de datos, como publicaciones de blog con un título y un cuerpo, también puede hacer una búsqueda más “interesante” en ellos, como:
SELECT * FROM BLOG_POSTS WHERE titulo like '%2019%' OR cuerpo like '%2019%';Ahora la consulta anterior también arrojaría algunos resultados, pero ¿cuál es el mejor orden para estos resultados? ¿Tiene sentido que una publicación de blog que coincida porque el número de teléfono 444220192 estaba dentro de su cuerpo, sería devuelta antes de una que tenga el título “El mejor equipo de fútbol de 2019”? La última coincidencia es definitivamente más relevante, pero una simple coincidencia con comodines no sería capaz de hacerlo.
Y debido a eso, agregar una búsqueda de texto completo en su sitio podría ser de gran valor (especialmente si deseas que tus usuarios busquen contenido no estructurado, como preguntas frecuentes o documentos descargables).
Implementando full text
Estos son los casos de uso que dejan atrás las búsquedas básicas con comodines. Por supuesto, las bases de datos SQL más comunes, como MySQL y PostgreSQL, han incluido algún tipo de capacidades básicas de texto completo, pero si desea aprovechar al máximo esta técnica, necesita un motor de búsqueda dedicado, como Elastic.
La forma en que funcionan estos motores es creando lo que se conoce como un “Índice invertido”. En el contexto de nuestro ejemplo, donde estamos tratando de indexar documentos de texto, se toma cada palabra de cada documento y se registra tanto la referencia al documento en el que aparecen como la posición dentro de él. Entonces, en lugar de tener que buscar su subcadena dentro de cada documento (como lo haría con los ejemplos SQL anteriores), solo necesita buscar la subcadena dentro del indice de palabras, y automáticamente sabremos en que documentos aparecen dichas palabras..
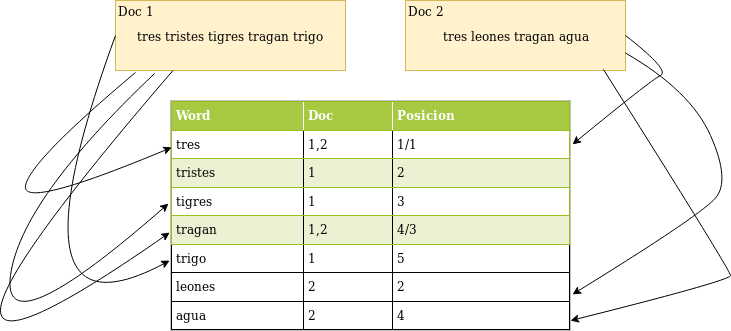
El diagrama anterior muestra de manera muy simplificada cómo se construye un índice invertido:
- Cada palabra aparece en el índice
- Se almacena una referencia al documento fuente en cada palabra (se permiten múltiples referencias a diferentes documentos)
- Dentro de cada documento, también registramos la posición de la palabra (columna # 3)
Con esta información, simplemente podemos buscar en el índice y hacer coincidir la consulta y las palabras en el índice (incluso podemos buscar usando subcadenas y aún así obtener resultados válidos).
Esto todavía no nos da lo que necesitamos, ya que no tenemos ninguna información sobre la relevancia. ¿Qué es más importante una coincidencia en el título o el cuerpo? ¿Un partido completo o parcial? Estas son reglas que nuestro motor necesitaría saber al buscar y, afortunadamente, el motor con el que vamos hoy (Elastic) se encarga de eso y más.
Entonces, tomemos este índice invertido básico y veamos cómo podemos usar Elastic para aprovechar esta técnica.
Implementando Elastic
Instalar y ejecutar una versión local de Elastic es realmente muy sencillo, especialmente si sigue las instrucciones oficiales.
Una vez que lo tenga en funcionamiento, podrá interactuar con él utilizando su API RESTful y cualquier cliente HTTP que tenga a mano (utilizaré curl, que debería instalarse en el sistema operativo más común de forma predeterminada).
Una vez configurado, el verdadero trabajo puede comenzar. Para ello necesitamos algunos pasos básicos
- Crear un indice
- Crear un mapeo para los documentos dentro del indice
- Cuando los pasos 1 y 2 estén listos ya podemos comenzar a crear documentos.
- Realizar búsquedas
Y para que las cosas sean más fáciles de entender, supongamos que estamos creando una API de biblioteca, una que permitirá buscar a través del contenido de diferentes libros digitales.
Al final de este artículo, mantendremos los metadatos al mínimo, pero es posible agregar todo lo que necesiten para su caso de uso particular. Los libros se descargarán del Proyecto Gutenberg y se indexarán manualmente al principio.
Creando el primer indice
Cada documento indexado en Elastic debe insertarse, por definición, dentro de un índice, de esa manera es posible buscar fácilmente dentro del alcance que necesita si comienza a indexar objetos diferentes y no relacionados.
Si lo hace más fácil, puede pensar en un índice como un contenedor, y una vez que decida buscar algo, debe elegir un contenedor.
Para crear un nuevo índice, simplemente puede ejecutar esto:
curl -X PUT localhost:9200/librosCon esa línea, está enviando su solicitud a su host local (suponiendo, por supuesto, que está haciendo una prueba local) y utilizando el puerto 9200, que es el puerto predeterminado para Elastic.
La ruta “libros” es el índice real que se está creando. Una ejecución exitosa del comando devolvería algo como:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "libros"
}Por el momento, tenga en cuenta esa ruta y pasemos al siguiente paso, creando un mapa.
Creando un mapa para los documentos
Este paso es opcional, puede definir estos parámetros durante la ejecución de la consulta, pero siempre me ha resultado más fácil mantener una asignación externa en lugar de una que esté vinculada a la lógica de negocio de su código.
Aquí es donde puede configurar cosas como:
- ¿Qué tipo de coincidencia se puede hacer para el título de nuestros libros y el cuerpo (¿Es una coincidencia completa? ¿Usamos texto completo o coincidencia básica? Etc.)
- El peso de cada coincidencia. O, en otras palabras, ¿qué tan relevante es una coincidencia en el título frente a una coincidencia en el cuerpo?
Para crear una asignación para un índice en particular, deberá utilizar el punto final de las asignaciones y enviar el JSON que describe la nueva asignación. Aquí hay un ejemplo que sigue la idea anterior de indexar libros digitales:
{
"properties": {
"titulo": {
"type": "text",
"analyzer": "standard",
"boost": 2
},
"cuerpo": {
"type": "text",
"analyzer": "spanish"
}
}
}Este mapeo define dos campos, el título, que debe analizarse con el analizador estándar y el cuerpo, que, considerando que todos serán libros en inglés, utilizará el analizador de idiomas para inglés. También estoy agregando un impulso para las coincidencias en el título, lo que hace que cualquiera de ellas sea dos veces más relevante que las coincidencias en el cuerpo del libro.
Y para configurar esto en nuestro índice, todo lo que tenemos que hacer es usar la siguiente solicitud:
$ curl -X PUT "localhost:9200/books?pretty" -H 'Content-Type: application/json' -d'
{
"properties": {
"titulo": {
"type": "text",
"analyzer": "standard",
"boost": 2
},
"cuerpo": {
"type": "text",
"analyzer": "spanish"
}
}
}
'Una ejecución exitosa produciría un resultado como este:
{
"acknowledged" : true
}Ahora con nuestro índice y asignaciones listos, todo lo que tenemos que hacer es comenzar a indexar y luego realizar una búsqueda.
Como indexar contenido en elastic
Aunque técnicamente, podemos hacer esto sin escribir código, voy a crear un script rápido en Node.js para acelerar el proceso de enviar los libros a Elastic.
La narrativa será simple, leerá el contenido de los archivos de un directorio en particular, tomará la primera línea y lo tomará como título, y luego todo lo demás se indexará como parte del cuerpo.
Aquí está ese código simple:
const fs = require("fs")
const request = require("request-promise-native")
const util = require("util")
let files = ["60052-0.txt", "60062-0.txt", "60063-0.txt", "pg60060.txt"]
const readFile = util.promisify(fs.readFile)
async function indexBook(fid, titulo, cuerpo) {
let url = "http://localhost:9200/libros/_doc/" + fid
let payload = {
url: url,
body: {
titulo: titulo,
cuerpo: body.join("\n")
},
json: true
}
return request.put(payload)
}
( _ => {
files.forEach( async f => {
let libro = await readFile("./libros/" + f);
[titulo, ...cuerpo] = libro.toString().split("\n");
try {
let resultado = await indexBook(f, titulo, cuerpo);
console.log("Indexando resultado: ", resultado);
} catch (err) {
console.log("ERROR: ", err)
}
})
})();Todo lo que estoy haciendo es revisar la lista de libros que tengo en mi matriz y enviar su contenido a Elastic. El método utilizado para indexar es PUT, y la ruta es localhost:9200/libros/_doc/id-libro.
Claro que si su configuración es distinta tendrán que reemplazar el puerto y el host.
Realizar una búsqueda en elastic
Para consultar el índice, podemos usar la API REST de Elastic de la misma manera que lo hemos estado usando hasta ahora, o podemos pasar a usar la libreria Node.js oficial de Elastic.
Para hacer las cosas interesantes hagamos una consulta de búsqueda utilizando el módulo NPM de Elastic, la documentación esta en el link de arriba.
Un ejemplo rápido que debería ser suficiente para poner en práctica todo lo que hemos estado discutiendo hasta ahora, realizaría una búsqueda de texto completo en los documentos indexados y devolvería una lista ordenada de resultados, según la relevancia (que es el criterio predeterminado que utiliza Elastic) .
El siguiente código hace exactamente eso, déjame mostrarte:
var elasticsearch = require('elasticsearch');
var client = new elasticsearch.Client({
host: 'localhost:9200/libros'
});
let q = process.argv[2];
( async query => {
try {
const response = await client.search({
q: query
});
console.log("Resultados encontrados:", response.hits.hits.length)
response.hits.hits.forEach( h => {
let {_source, ...params } = h;
console.log("Resultado encontrado en el archivo: ", params._id, " with score: ", params._score)
})
} catch (error) {
console.trace(error.message)
}
})(q)El código anterior toma la primera palabra que usa como argumento CLI cuando ejecuta el script y lo usa como parte de la consulta.
Supongamos que buscamos la palabra “azul” en los libros que hemos indexado. Al correr el query el script nos mostraría algo asi:
Resultados encontrados: 2
Resultado encontrado en el archivo: 60052-0.txt with score: 2.365865
Resultado encontrado en el archivo: pg60060.txt with score: 1.7539438Gracias al hecho de que se usaron el nombre de archivo como índice del documento, es posible reutilizar esa información para mostrar resultados relevantes.
Esencialmente, ahora podemos descargar tantos libros como querramos e indexarlos utilizando el script de arriba. Y tenemos un motor de búsqueda, capaz de hacer una búsqueda rápida y devolver los nombres de archivo relevantes para que los abra. La velocidad aquí es uno de los beneficios de usar el índice invertido que mencioné anteriormente, ya que en lugar de tener que revisar todo el cuerpo de cada documento cada vez, solo buscará la palabra que ingrese dentro de su índice interno y devolverá la lista de referencias que hizo durante la indexación.
Como conclusión directa de esto, se podría decir con seguridad que indexar un documento es mucho más costoso (computacionalmente hablando) que buscar. Y como normalmente, la mayoría de los motores de búsqueda pasan la mayor parte de su tiempo buscando en lugar de indexar, eso es una compensación muy buena.
