Bien como he venido escribiendo algunos conceptos básicos de la arquitectura y diseño general de un compilador, voy a continuar a entrar en detalle sobre la fase de análisis Léxico de un compilador, y para ello vamos a dividir esta sección en dos partes:
- Conceptos y teoría
- Construcción de un analizador léxico con java
Siendo este post la primera parte.
El análisis Léxico es la primera fase de un compilador, y toma el programa fuente de los pre-procesadores que está escrito en forma de declaraciones. Este proceso entonces desglosa el código en una serie de tokens, deshaciéndose primero de todos los comentarios en el código y los espacios en blanco.
Si el analizador léxico encuentra un token que no es válido (ya hablamos de esto cuando describimos las fases del compilador) entonces se genera un error. El analizador léxico trabaja muy de cerca con el analizador sintáctico. Leemos caracteres de entrada a través del código fuente, revisamos que los tokens sean todos válidos y pasamos los lexemas al analizador sintáctico cuando este lo requiera.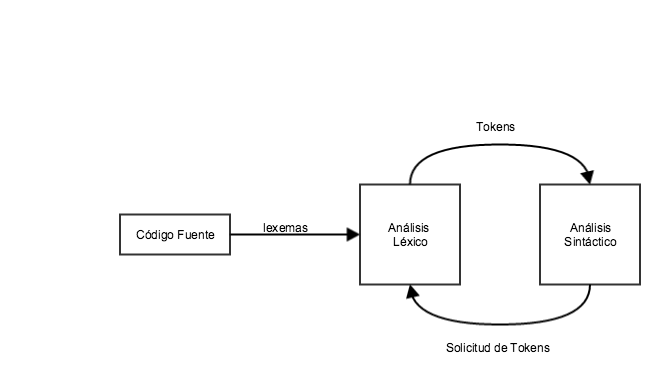
Tokens
Los lexemas son una secuencia de caracteres alfanuméricos en un token. Hay varias reglas predefinidas para cada lexema que sirven para identificarlos como un token válido. Estas reglas están definidas por gramáticas formales, que siguen un patrón, un patrón explica que es un token, y estos patrones pueden ser definidos a través de expresiones regulares.
En un lenguaje de programación, palabras reservadas, constantes, identificadores, cadenas de texto, números, operadores y signos de puntuación pueden ser considerados como tokens.
Consideremos la siguiente expresión
int valor = 100;
Al pasarla por un analizador léxico el mismo reconocerá cada uno de los tokens en la expresión.
int (palabra reservada) valor (identificador) = (operador) 100 (número/constante) ;(símbolo)
Especificaciones de un token
Hay algunos términos en la teoría de lenguajes formales que definiremos a continuación para entender mejor que es un token.
Alfabeto o Vocabulario
Es un conjunto finito de símbolos formalmente definidos en un lenguaje. por ejemplo:
- {0,1} Es un conjunto de símbolos para representar números binarios
- {0,1,2,3,4,5,6,7,8,9,A,B,C,D,E,F} Es un conjunto de símbolos para representar números hexadecimales
- {a-z, A-Z} Es un conjunto de símbolos para representar palabras en idioma español o ingles (según sea el caso).
Cadenas o Strings
Una cadena es una secuencia finita de alfabetos cuya longitud es el numero de ocurrencias de un símbolo perteneciente a esos alfabetos, por ejemplo la longitud de “compiladores” es 12 y estaría denotada como |compiladores| = 12. Una cadena con longitud cero es conocida como una cadena vacía y esta denotada por la letra griega epsilon ?.
Símbolos Especiales
Un lenguaje típico de alto nivel contiene los siguientes símbolos:
| Símbolos Aritmeticos | Suma(+), Resta(-), Modulo(%), Multiplicación(*), División(/) |
| Símbolos De Puntuación | ,Coma (,), Punto y Coma (;), punto (.), arrow (->) |
| Asignación | = |
| Asignaciones Especiales | +=, /=, *=, -= |
| Comparación | ==, !=, <, <=, >, >= |
| Pre-procesador | # |
| Especificador de Ubicación | & |
| Operadores Logicos | &, &&, |, ||, ! |
| Operadores de desplazamiento | >>, >>>, <<, <<< |
Lenguaje
Un lenguaje es considerado un conjunto finito de cadenas que a su vez se construyen de un conjunto finito de alfabetos. Los lenguajes de computadoras son considerados como conjuntos finitos y matemáticamente un conjunto de operaciones finitas que pueden ser ejecutados por los mismos. Entonces los lenguajes finitos pueden ser descritos en términos de expresiones regulares.
Regla de Coincidencia Mas Larga
Cuando el analizador lexico lee el código fuente, busca en el codigo letra por letra y cuando encuentra un espacio en blanco, un operador, o algún simbolo especial decide si una palabra esta completada.
por ejemplo
int intvalue;
Mientras busca en los lexemas hasta encontrar el espacio en blanco después de ‘int’ el analizador léxico no puede determinar si es una palabra reservada o los caracteres iniciales de un identificador que comienza con ‘int’ quizás ‘interno’
La regla de coincidencia mas larga establece que el lexema escaneado debería ser determinado basándose en la regla de coincidencia mas larga dentro de todos los tokens que ya se encontraron.
El analizador léxico también sigue reglas de prioridad, por ejemplo: a una palabra reservada del lenguaje se le da prioridad ante un identificador que el programador ha definido, es decir, que si el programador nombra una variable igual que una de las palabras reservadas mas tarde el analizador sintactico, deberá generar un error.
Very nice!