El proceso de compilación es una secuencia de varias fases. Como ya lo habíamos dicho en post anteriores, cada fase toma su información de entrada de la fase anterior, y cada fase tiene su propia interpretación del código fuente. Para ilustrar mejor las fases del compilador veamos el siguiente diagrama de bloques:
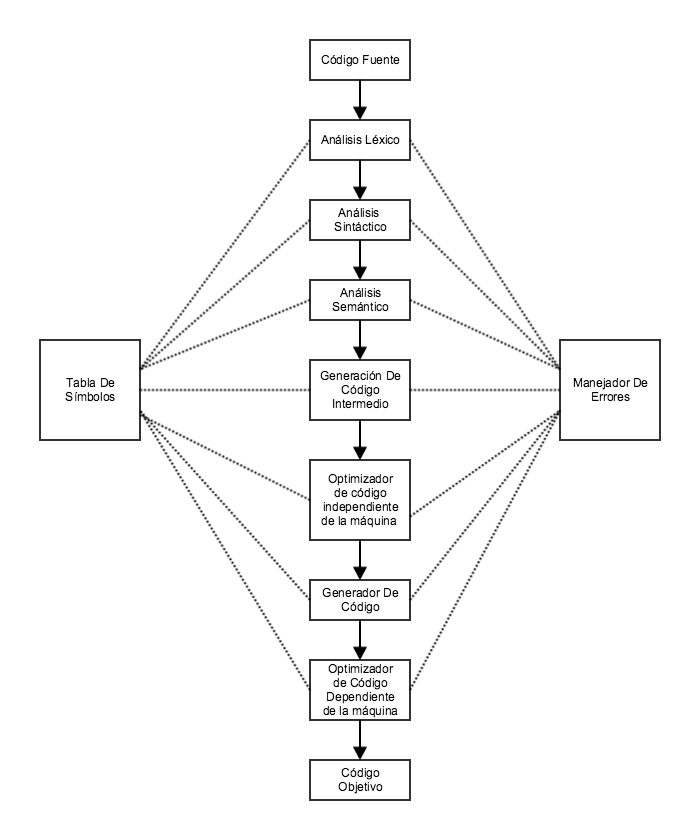
Introducimos entonces los conceptos básicos del proceso de compilación que en post futuros veremos mas a detalle con ejemplos prácticos, usando distintos tipos de tecnología.
Análisis Léxico
Asi como todos los idiomas tiene un alfabeto de caracteres válidos (e.g: español, chino, japonés), cada lenguaje tiene su propio conjunto de caracteres aceptados. Algunos lenguajes tienen un alfabeto muy reducido como brainfuck que consta de solo 8 caracteres, hasta los mas extensos y conocidos como java, python o javascript.
Ahora bien, la fase de análisis léxico se encarga de convertir el codigo fuente del usuario en un stream de caracteres que al final se convierten en un conjunto de lexemas con significados específicos que denominamos tokens.
Análisis Sintáctico
Esta fase que le sigue al análisis léxico, la llamamos Análisis sintáctico o en ingles parsing o como muchos programadores le dicen parseo (aunque según la RAE no existe tal vocablo… aun) En esta fase se toma el conjunto de tokens producidos por la fase de análisis léxico y se genera un árbol de sintaxis, luego este se revisa de acuerdo a la gramática formal del lenguaje definido y se verifica que las expresiones construidas por el arreglo de tokens sean sintacticamente correctos.
Análisis Semántico
El análisis semántico valida si el árbol sintáctico construido concuerda con las reglas del lenguaje formal. Por ejemplo, asignaciones de valores entre tipos de datos que son compatibles. En esta fase también es muy necesario mantener un control de los identificadores con sus respectivos tipos y expresiones, por ejemplo si una variable es asignada sin haber sido declarada, y produce como salida un árbol de sintaxis anotado.
Generación de código intermedio
Después de haber conducido el análisis semántico el compilador genera un código intermedio entre el código fuente y el el código de la maquina objetivo (unos y ceros). Este representa un programa para una máquina abstracta. Esta en medio de un lenguaje de alto nivel y un lenguaje de máquina. Este código intermedio debe ser generado de tal manera que es fácilmente traducido a un legunaje de máquina de bajo nivel.
Optimización
La siguiente fase realiza una optimización del código intermedio generado. La optimización puede asumirse como algo que quita lineas de código innecesarias, y ordena una secuencia de declaraciones que aceleran la ejecución del programa sin desperdiciar recursos de CPU o memoria RAM.
Por ejemplo si tenemos las siguientes lineas en código intermedio.
int valorA = 0; int valorB = 10; int temp = valorA + ValorB;
El optmizador lograría que este código se viera reducido así
int temp = 0 + 10;
reduciendo así el espacio reservado para las dos variables iniciales y los ciclos de reloj que toma asignarlos.
Generación De Código
En la fase de generación de código se toma la versión optimizada del código intermedio y se mapea a la lenguaje de máquina objetivo. La generación de código traduce entonces el código intermedio en una secuencia reubicable de código de máquina, mas tarde el enlazador del sistema operativo tomara estas instrucciones y les asignara un espacio en la memoria para así poder funcionar.
Tabla de símbolos
Es importante entender que la tabla de símbolos no es mas que una estructura de datos que denominamos matriz ortogonal, que es una tabla con posiciones de memoria dinámicas sobre las cuales se puede realizar búsquedas y editar los valores de cada una de sus celdas.
El compilador se vale de esta estructura de datos para almacenar identificadores, tipos y valores de las variables a lo largo de todo el proceso de compilación, de forma que sea fácil y rápido obtener cualquiera de las propiedades de un símbolo.
Ejemplo rápido
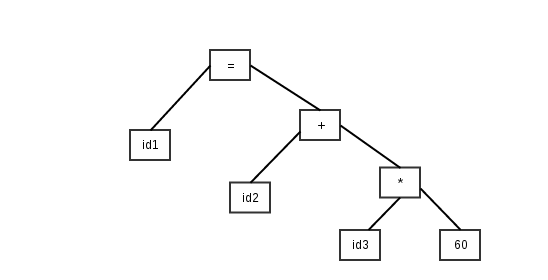
Supongamos que necesitamos compilar la siguiente expresión
precio = costo + impuesto * 60
El análisis léxico nos dice que tenemos 3 elementos, identificadores, operadores y un valor constante, y produce lexemas de este modo
id1 = id2 + id3 * 60
El análisis sintáctico produce un árbol sintáctico así:
El análisis semántico lograría reconocer la constante como un numero entero y produciría un árbol anotado así
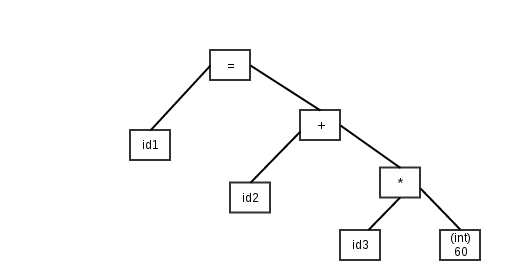
Luego se genera el código intermedio
temp1 = int(60) temp2 = id3 * temp1 temp3 = id2 + temp2 id1 = temp3
Luego este código sería optimizado así
temp1 = id3 * 60 id1 = id2 + temp1
Y finalmente se generaría código ensamblador listo para ser ejecutado
MOVF id3, R2 MULF #60, R2 MOVF id2, R1 ADDF R2, R1 MOVF R1, id1
[…] analizador léxico encuentra un token que no es válido (ya hablamos de esto cuando describimos las fases del compilador) entonces se genera un error. El analizador léxico trabaja muy de cerca con el analizador […]
¡Genial! Gracias. Todo esto me lleva a mis años de universidad, cuando jugábamos con LEX y YACC.