
Hasta ahora en posts anteriores hemos visto como instalar y configurar instancias de jenkins en sus diferentes sabores y funcionalidades. Es momento entonces de que comencemos a hacer que jenkins trabaje en nuestra entrega continua.
Un pipeline es una secuencia de operaciones automatizadas que usualmente representa una parte de la entrega y el aseguramiento de la calidad del software. Podemos verlo simplemente como una secuencia de scripts que provee algunos beneficios como:
- Agrupación de operaciones Las operaciones se agrupan en etapas que llamaremos stages, pero también son conocidas como gates o quality gates estas introducen una estructura del proceso y definen claramente una regla: si un stage falla, ningun otro stage se ejecuta.
- Visibilidad Todos los aspectos del proceso son visualizados, lo que puede ayudar a un análisis del fallo rápido y promueve la colaboración de los equipos.
- Retroalimentación Los miembros del equipo se dan cuenta de los problemas tan pronto como ocurren. Esto les permite reaccionar de manera rápida.
Estructura de un pipeline
Un pipeline de jenkins consiste de dos clases de elementos: stages y pasos (steps).
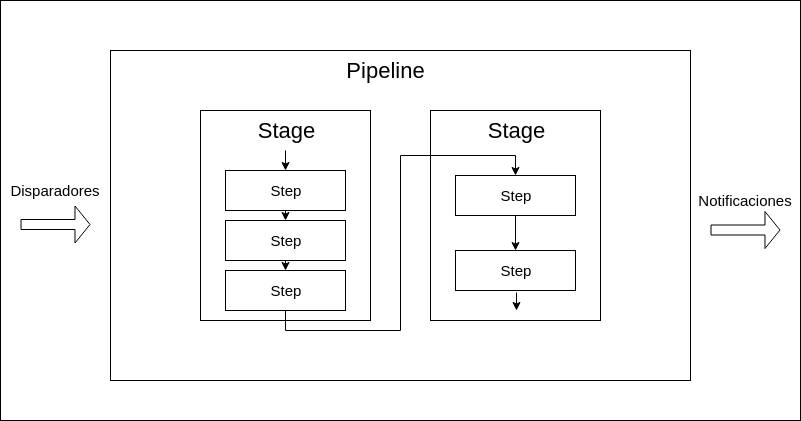
Entonces los pipelines tienen dos componentes fundamentales:
- Step: Representa una sola operación (le dice a jenkins que hacer, por ejemplo, clonar un repositorio o ejecutar un script)
- Stage: Es una separación lógica de los steps. Es decir grupos de secuencias conceptualmente distintas. que se usan para visualizar el progreso en jenkins. Lo mas común es que tengamos Stages como: Compilar, Probar e Instalar.
Los stages y los pasos se pueden configurar muy fácilmente a través de la interfaz gráfica de jenkins. Para ello tendriamos que escribir un script:
pipeline {
agent any
stages {
stage('Stage: Hola Mundo') {
steps {
echo 'Paso 1. Hola Mundo'
}
}
stage('Stage: Segundo Stage') {
steps {
echo 'Paso 2: Hola Dos Veces'
echo 'Paso 3. Hola Tres Veces'
}
}
}
}
Para configurarlo debemos ir a la opción de “Nueva Tarea” en la interfaz:
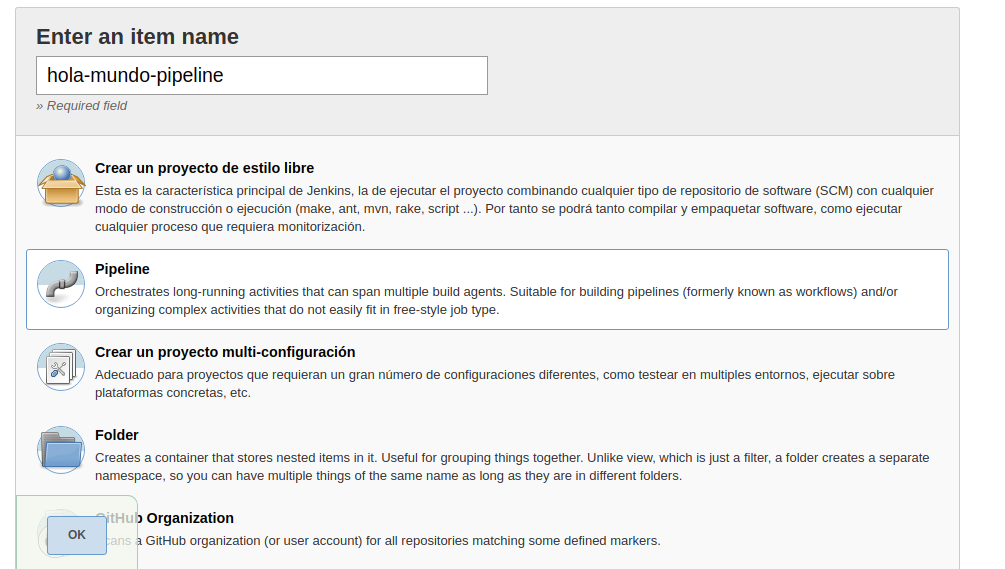
Luego nombramos la tarea y seleccionamos la opción pipeline:
Vemos las configuraciones son varias, pero para este ejemplo de hola mundo vamos a dejarlo todo en blanco
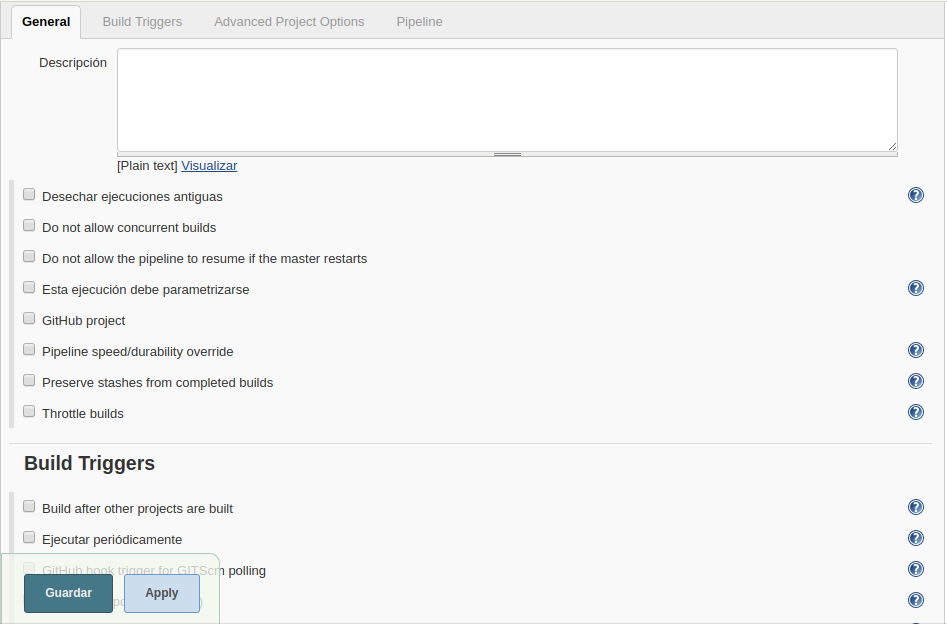
Vamos a la pestaña que pone “Pipeline” e introducimos el script que acabamos de idear.
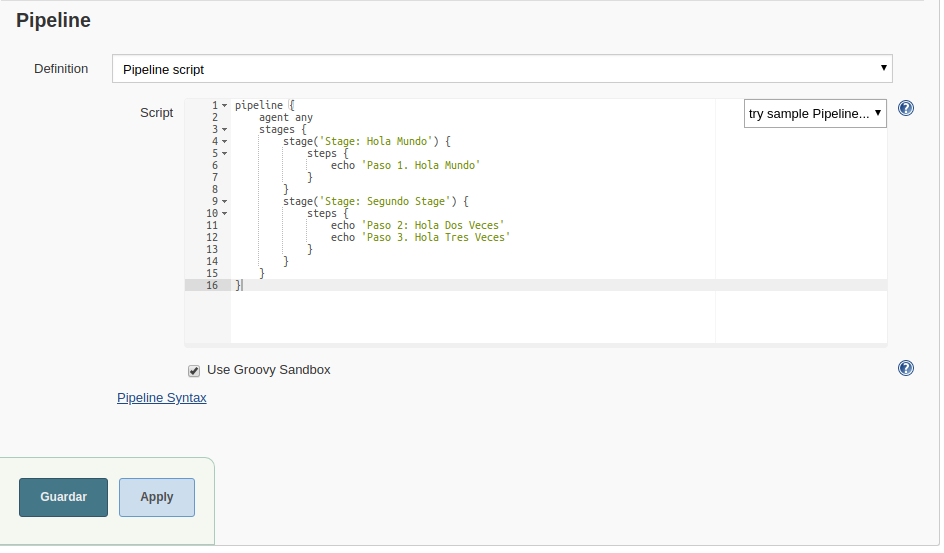
Bien, ahora lo guardamos y en la pagina principal lo ejecutamos haciendo clic en donde dice “Construir Ahora” o “Build Now”. De inmediato vemos como el pipeline comienza a ejecutarse en cada uno de sus stages:
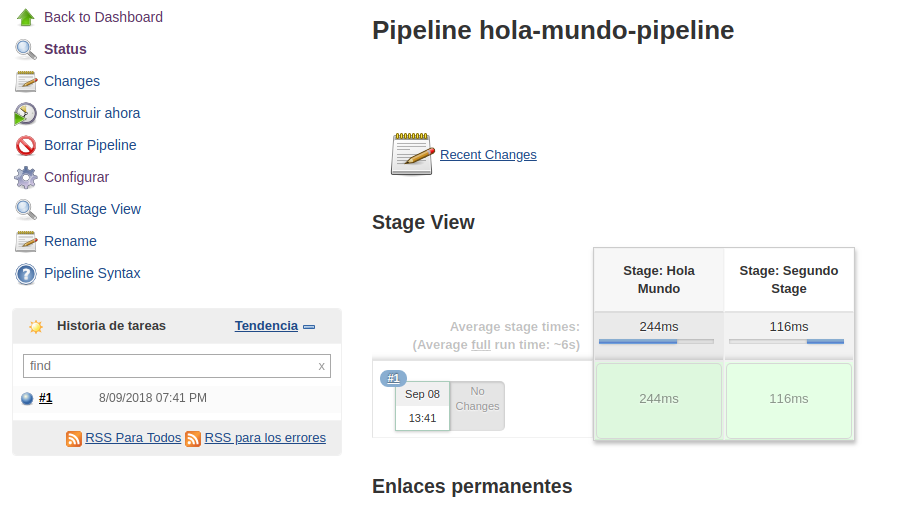
Ahora veamos un pipeline un poco mas complejo para después explicarlo:
pipeline {
agent any
triggers { cron('* * * * *') }
options { timeout(time: 5) }
parameters {
booleanParam(name: 'DEBUG_BUILD', defaultValue: true,
description: 'Es esto un build para depurar?')
}
stages {
stage('Example') {
environment { NAME = 'Debug' }
when { expression { return params.DEBUG_BUILD } }
steps {
echo "Hola desde $NAME"
script {
def browsers = ['chrome', 'firefox']
for (int i = 0; i < browsers.size(); ++i) {
echo "probando el browser ${browsers[i]}."
}
}
}
}
}
post { always { echo 'Siempre es bueno decir hola!' } }
}
Ahora veamos paso a paso que es lo que hace el anterior pipeline:
- Utiliza cualquier agent disponible
- Se ejecuta automáticamente cada minuto
- Se detiene si la ejecución tarda mas de 5 minutos
- Pregunta si el parámetro DEBUG_BUILD es verdadero
- Configura la variable NAME para que su valor sea “Debug”
- Si el parámetro es verdadero:
- imprime “Hola desde Debug”
- imprime “Probando el navegador Chrome”
- imprime “Probando el navegador Firefox”
- Imprime “Siempre es bueno decir hola!” Sin importar si la ejecución termina con o sin errores
Cuando estamos haciendo uso de los pipelines es importante conocer todas las palabras clave que estan disponibles para idear los scripts que nos ayudaran a dicha tarea.
Estas están documentadas a profundidad en la documentación:
https://jenkins.io/doc/book/pipeline/syntax/
Los bloques dentro de un pipeline declarativo pueden contener únicamente 3 cosas: Secciones, Directivas y Pasos (Sections, Directives, Steps)
Secciones (Sections)
Las secciones en un pipeline declarativo contienen Directivas y Pasos (Directives, Steps) y definen la estructura del mismo.
Usualmente las palabras clave que veremos en las secciones son:
- Stages Define una serie de una o mas directivas del tipo stage
- Steps Define una serie de una o mas directivas del tipo step
- Post Define una seria de una o mas instrucciones que corren al final del pipeline y estan marcados con una condición, tal como: always, success o failure. Usualmente se usan para enviar notificaciones de el resultado final de dicho pipline.
Directivas (directives)
Las directivas expresan la configuración del pipeline
- Trigger Esta sección define las formas automatizadas en las cuales un pipeline debería ejecutarse de nuevo. En nuestro ejemplo el comando cron indica una frecuencia de tiempo. Hay 3 disponibles
- cron Acepta un string al estilo “cron” para definir la frecuencia con la que el pipeline se debe ejecutar
- upstream Acepta un string con nombres de jobs separado por comas y un limite. Entonces cuando uno de los jobs en el string llega a su limite, el pipeline se ejecuta de nuevo.
- pollSCM Acepta un string al estilo “cron” que define un intervalo sobre el cual se deben buscar nuevos cambios en el sistema de control de versiones.
- Agent Define que tipo de agente estaremos usando
- Options Hay un buen numero de opciones que hacen diferentes cosas:
- buildDiscarder Persiste artefactos y salida de consola para un número especifico de ejecuciones
- checkoutToSubdirectory clona el repositorio en cuestión en un sub-directorio del espacio de trabajo
- disableConcurrentBuilds Prohíbe la ejecución concurrente del pipeline. Útil para cuando se acceden a recursos compartidos
- newContainerPerStage cuando esta especificado cada stage creara un nuevo contenedor de docker en el mismo nodo, en lugar de correr todos los stages en el mismo contenedor.
- overrideIndexTriggers Permite sobre escribir el valor por defecto de los disparadores que indexan las ramas (branch) en el sistema de control de versiones.
- preserveStashes preserva el código de los últimos n trabajos terminados. En caso de ser necesario repetir la compilación.
- quietPeriod Configura el periodo de inactividad en segundos para el pipeline.
- retry reintenta el pipeline en caso de fallo
- skipDefaultCheckout Saltearse clonar el código del repositorio default configurado en el agent
- skipStagesAfterUnstable no ejecutar stages después de que la compilación resulto en “intestable”
- timeout como en el ejemplo, configura un tiempo máximo para que la compilación termine. Después de este tiempo jenkins cancelará el pipeline.
- Environment Define un conjunto de llave valor, que se usa para definir variables de entorno
- Parameter Define una lista personalizada de parámetros disponibles durante la ejecución del pipeline
- Stage permite la agrupación lógica de steps (como ya habíamos dicho antes)
- When Determina si un stage debería ser ejecutado dependiendo de la condición que defina.
Pasos (Steps)
Los steps son la parte mas fundamental de un pipeline. Definen las operaciones que van a ser ejecutadas.
- sh define un comando de terminal. Abre un shell y lo ejecuta. Es posible definir casi cualquier operación usando este tipo de paso
- custom Jenkins nos ofrece muchas operaciones que se pueden usar como steps. (por ejemplo echo) muchos de ellos simplemente envuelven instrucciones sh para que sean mas fáciles de usar. Por conveniencia los plugins también pueden definir sus propias operaciones
- script Estos ejecutan un bloque de código escrito en groovy que pueden ser usados para escenarios no comunes en donde se necesita algún tipo de control de flujos.
Ahora bien, ya basta de ejemplos “hola mundo”!. Vamos a definir un pipeline funcional que clona, compila y prueba un repositorio.
Definimos nuestro pipeline asi:
pipeline {
agent any
stages {
stage("Clonar") {
steps {
git url: 'https://github.com/ejemplo/gradle.git'
}
}
stage("Compilar") {
steps {
sh "./gradlew compileJava"
}
}
stage("Probar") {
steps {
sh "./gradlew test"
}
}
}
}
Lo guardamos como ya hemos dicho y ya tenemos nuestro artefacto creado y listo para ser usado. Noten que en el paso de Clonar, el repositorio no existe. Deben ustedes crear su propio repositorio y modificar los comandos para compilarlo y probarlo.
En el caso particular de este ejemplo, es un proyecto de java que se compila y se prueba usando gradle en lugar de maven. Pero esto es cuestión de que lo ajusten a su gusto y a su proyecto.
Conclusión
Jenkins es una herramienta poderosa, que nos permite definir nuestro proceso de integración continua de manera ordenada y lógica. Por lo tanto, es importante conocer a profundidad todas las opciones que juegan a nuestro favor a la hora de llevar a cabo nuestros esfuerzos de integración continua.
[…] revisan en el post donde configuramos el pipeline definimos una sección que se llamaba post. Esta es la sección que por lo general se usa para […]
Muy bueno. Gracias!
Muy bien. ¡Muchas gracias!